Release It! Design and Deploy Production-Ready Software by Michael T. Nygard, published by The Pragmatic Programmers.
ISBN: 978-0-9787-3921-8
Introduction
Release It! is a book I have had on my reading list for a few years. I started a new job at Tradera/eBay Sweden in June last year and Release It! felt more relevant to my work than ever before. It’s the first time in my career that I am working on a public site with a lot of traffic (well, a lot for Sweden anyway). Downtime can mean a lot of lost revenue for my company. As I’m on call every second month for a week at a time, downtime also really affects how much sleep I get during that week. So perfect timing to read a book about pragmatic architecture.
System downtime can both cost huge amounts of money and seriously damage the reputation of a company. The incident that springs to mind when I think about damage to a company’s reputation is the Blackberry three day outage in 2011. It was the beginning of the end for a previously very successful company. Release It! is all about building a pragmatic architecture and infrastructure to avoid one of these doomsday scenarios for your company.
The book is organised into four different parts and roars into action with the first part: Stability or how to keep your system up 24 hours a day.
The Exception That Grounded An Airline
The author Michael Nygard has worked on several large, distributed systems and uses his war stories to illustrate anti-patterns.
The first story is of a check-in system for an airline that crashes early in the morning – peak time for check-ins. First, he describes the process of figuring out which servers were the problem (they had no errors in their logs). They then took the decision to restart them all. This restart took three hours and caused so many flight delays that it made the TV news. The post-mortem involved thread dumps and decompiling production binaries (there was bad blood between the developers and operations so they weren’t too keen to give him the source code). The bug turned out to be an uncaught sql exception that only ever got triggered during a database failover.
I love the this way of illustrating technical concepts. The stories are great and make the book a very easy read despite it being quite technical. And the postmortems after the incident are like CSI for programmers.
The lesson learned in this case was that it is unlikely that you can catch all the bugs but that you CAN stop them spreading and taking down the whole system. This bug was a simple bug but one unlikely to be ever caught in testing. Who tests that code works during database failovers and has that setup in their test environment?
However, by failing fast and using patterns like timeouts or circuit breakers you can stop the problem spreading through the whole system and crashing everything.
Cascading Failures vs Fail Fast
 After setting the scene, the author then introduces a group of Stability anti-patterns. They have great names like Cascading Failures and Attacks of Self-Denial. These anti-patterns represent all the ways you can design an unstable system.
After setting the scene, the author then introduces a group of Stability anti-patterns. They have great names like Cascading Failures and Attacks of Self-Denial. These anti-patterns represent all the ways you can design an unstable system.
To counteract these anti-patterns are a group of Stability patterns.These include some very useful patterns like the practice of using timeouts so that calls don’t hang forever. Fail Fast counteracts the Cascading Failure anti-pattern. Instead of an error being propagated from subsystem to subsystem crashing each one, the idea is to fail as fast as you can so that only the subsystem where the error occurred is affected.
The most interesting pattern for me was the Circuit Breaker pattern. I haven’t used it yet in a production system but it got me looking at a .NET implementation called Polly.
Anyone else used it in a production system?
Capacity
The second part of the book introduces the capacity theme with a story about the launch of a retailer’s new website. They deployed the site at 9 a.m. and by 9:30 a.m. it had crashed and burned. Total nightmare. One of the sysadmins had a 36 hour shift setting up and deploying new app servers.
Again the author introduces a group of anti-patterns to watch out for and some patterns to counteract them. This time the anti-patterns are more obvious and are mostly some sort of waste of resources. They can be seemingly insignificant anti-patterns like not creating indexes for lookup columns in a database table, session times that are too long (a session in memory is using valuable memory), sending too much data over the wire or cookies that are too large. For a small system these are not a problem but if you multiple them with thousands of concurrent users then a lot more servers will be needed.
Michael Nygard makes a very good point here that most developers have less than 10 years of experience and most systems that are built do not have capacity problems; the combination of these two statistics means that very few developers have experience of working on large systems. This also means that the same mistakes are repeatedly made when designing large systems.
I personally still have a lot to learn here. I will be digging deeper into load testing and some of the more technical details of how our servers are configured. It’s easy to forget about how the code that I write affects the production environment.
General Design Issues
This part of the book is a collection of disparate design issues that can be important for large systems. Networking, security, load balancing, SLA’s, building a QA environment and other topics are covered here. Interesting stuff if not as compelling as the first two parts of the book.
Operations
The last part of the book kicks off with another great war story about a site suffering performance problems on Black Friday (the day after Thanksgiving in the US when every shop in the country has a sale). This time the problem was caused by an external system run by another company that had taken down two of its four servers for maintenance (on the busiest day of the year!). They were able to save the situation by reconfiguring a component not to call the external servers. This was possible due to good component design that allowed them to just restart the component instead of the server (it would have taken 6 hours to restart all the servers). The site was back working within a few minutes.
Transparency
So how did they know so fast what was wrong in this case? They had built the system to be transparent. Most systems are black boxes that do not allow any sort of insight into how healthy it is. To make a system transparent it is has to be designed to reveal its current state and a monitoring infrastructure is needed to create trends that can be easily analyzed by a human.
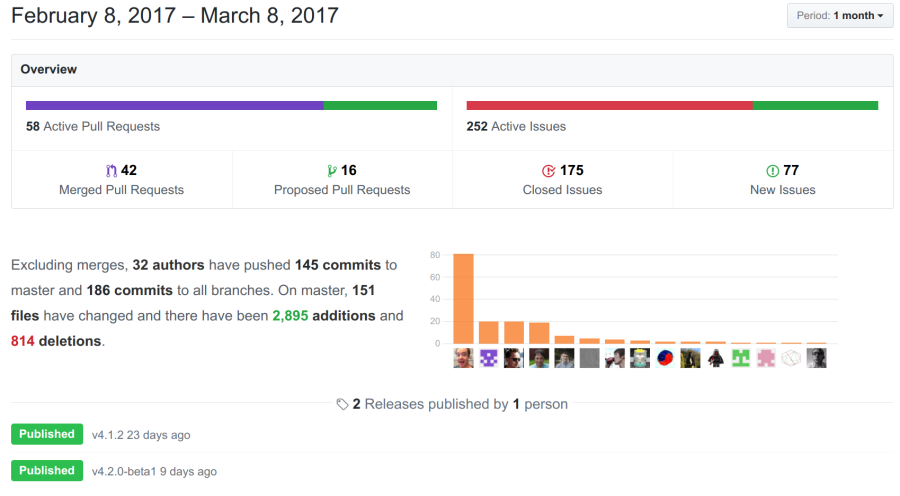
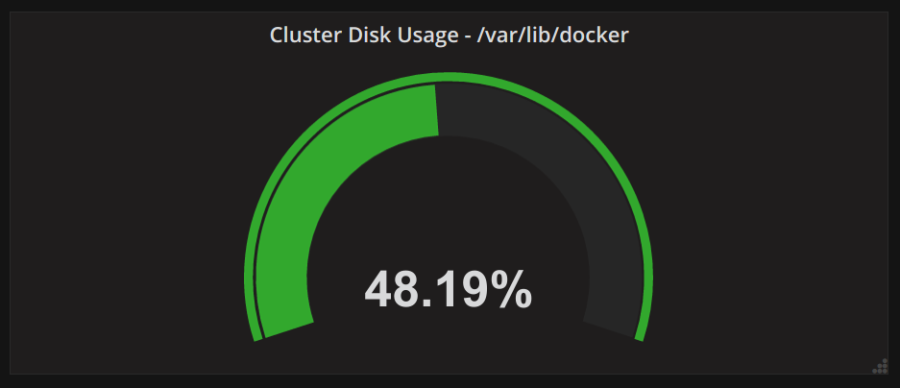
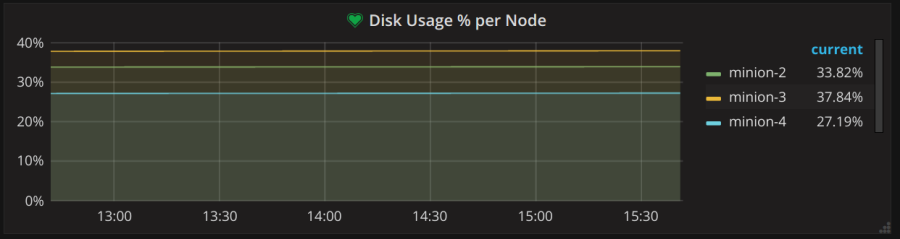
For example, at Tradera/eBay Sweden for our frontend servers we can see the number of errors per minute, page response time (both client and server side) and number of 404 and 500 HTTP response per minute (as well as lots of other measurements). For each server we can see memory usage, number of connections and a host of other performance indicators. By just glancing at our dashboard for live statistics I can see if we are suffering any performance issues on the frontend. Without this help it would be extremely difficult to keep the system running when things go wrong. As you can see this theme is close to my heart!
I did get a bit lost in the technical details of this section however. It is a really interesting theme but the technical details are either JVM-specific or have not aged well. A lot has happened in this space since the book was written in 2007.
Verdict
If you work with a system that is deployed on more than ten servers then this book is a must-read. There is a difference between just writing code and keeping a system up 24 hours a day. If you burn for Devops or are on-call regularly or care about creating stable systems then this book is for you.













You must be logged in to post a comment.